当我们需要大量获取网上的信息时,手动一个个获取必然会浪费大量的时间和精力,这时我们可以按照一定的规则编写程序,帮助我们收集信息,这就是爬虫。
网上的爬虫工具不可胜数,对于前端开发者来说Selenium是个不错的选择:支持多种编程语言(C#、Javascript、Java、Python、Ruby),并且是直接在浏览器中运行,就跟真实的用户一样。
安装起来十分简单:
npm install selenium-webdriver
下载和自己浏览器版本对应的组件,并放到项目根目录下:
编写爬虫程序需要有四个步骤:
- 明确目标
- 业务分析
- 收集信息
- 储存数据
一、明确目标
以爬虫的“Hello World”,豆瓣Top250为例,抓取每部电影的名称、年份、评分、演员等信息。
二、业务分析
250部电影共分为10页显示,每页显示25部电影,参数start决定从第几部开始显示。我们需要先获取到每部电影的内容页面链接,然后访问该页面获取里面的信息,根据该需求我们不难写出下面两个函数:
/**
* 在电影列表页面获取每部电影内容页面链接
* @returns String[] 链接数组
*/
const getMovieLinks = () => Array.from(document.querySelectorAll('.grid_view .info a')).map(link => link.href)
const getData = () => {
const $rating = document.querySelector('#interest_sectl')
return {
'name': document.querySelector('[property="v:itemreviewed"]').innerText,
'year': document.querySelector('.year').innerText.substr(1, 4),
'rating': {
'average': $rating.querySelector('[property="v:average"]').innerText,
'count': $rating.querySelector('[property="v:votes"]').innerText,
'weights': Array.from($rating.querySelectorAll('.rating_per')).map((rating) => rating.innerText)
},
'director': document.querySelector('#info span:first-child .attrs').innerText,
'leading': Array.from(document.querySelectorAll('#celebrities .celebrity a.name')).map((leading) => leading.innerText),
'categories': document.querySelector('#info [property="v:genre"]').innerText,
}
}
有了这两个核心函数,剩下的工作就只剩下往对应的页面里执行函数了。
三、收集信息
const { Builder } = require('selenium-webdriver')
const driver = new Builder().forBrowser('chrome').build()
const getMovieLinks = // 上面定义的函数
const getData = // 上面定义的函数
;(async () => {
/**
* 访问电影列表页面,在里面执行getMovieLinks函数获取每部电影内容页面的链接
*/
const links = [];
for (let i = 0; i < 250; i += 25) {
await driver.get(`https://movie.douban.com/top250?start=${i}`)
links.push(...await driver.executeScript(getMovieLinks))
console.log(`getting links ${i}`)
}
/**
* 分别访问上面获取到的链接,执行getData获取电影信息
*/
const movies = [];
for (let i = 0, len = links.length; i < len; i ++) {
await driver.get(links[i])
const movie = await driver.executeScript(getData)
movie.rank = i + 1
movies.push(movie)
console.log(movie)
}
// 退出浏览器
await driver.quit()
})()
理论上来说,上面的代码已经没什么问题了,应该能收集到所有电影的信息,尝试执行:
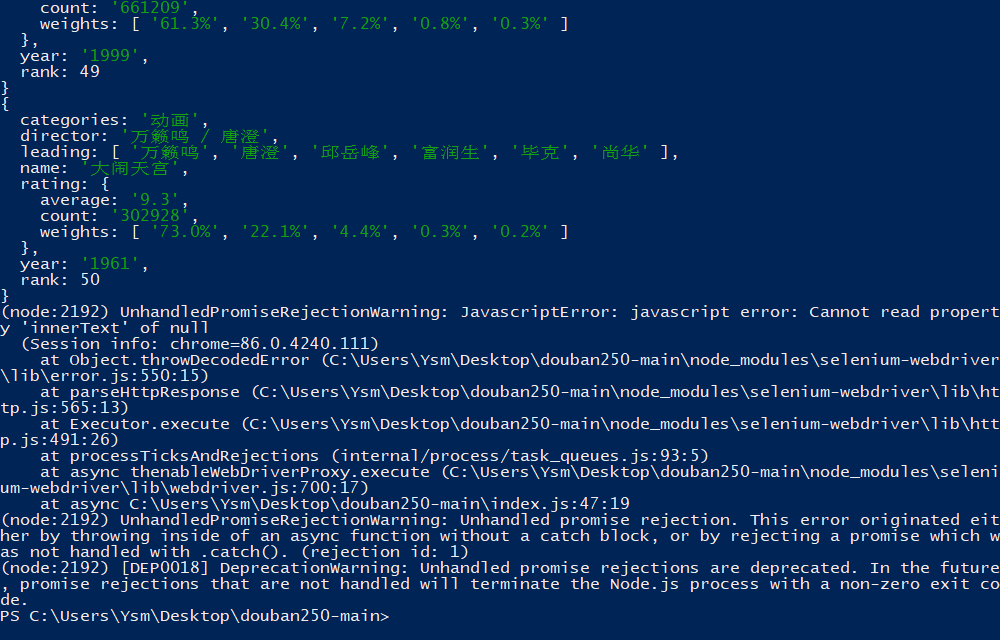

每次执行都会在不同的页面出现报错,当把getData函数放到该页面的控制台执行时却又不会出现,因此该错误可能是因为页面未加载就执行代码引起的,所以可以稍微升级一下getData函数:
const getMovieData = (callback) => {
let finished = false
const getData = () => {
if (finished) return
const $rating = document.querySelector('#interest_sectl')
// onload和setTimeout是异步执行的,要用callback替换return实现返回
callback({
'name': document.querySelector('[property="v:itemreviewed"]').innerText,
'year': document.querySelector('.year').innerText.substr(1, 4),
'rating': {
'average': $rating.querySelector('[property="v:average"]').innerText,
'count': $rating.querySelector('[property="v:votes"]').innerText,
'weights': Array.from($rating.querySelectorAll('.rating_per')).map((rating) => rating.innerText)
},
'director': document.querySelector('#info span:first-child .attrs').innerText,
'leading': Array.from(document.querySelectorAll('#celebrities .celebrity a.name')).map((leading) => leading.innerText),
'categories': document.querySelector('#info [property="v:genre"]').innerText,
})
finished = true
}
// 处理页面未加载完成就执行getData引起的报错
try {
getData()
} catch (e) {
onload = getData
}
// 极小几率会出现上面代码不执行的情况,延迟两秒执行保底
setTimeout(getData, 2000)
}
前面的代码也需要升级为:
;(async () => {
// ...
const movies = [];
for (let i = 0, len = links.length; i < len; i ++) {
// ...
const movie = await driver.executeAsyncScript(getMovieData)
// ...
}
// ...
})()
再重新执行,问题已经得到解决。

四、储存数据
movies数组中已经包含了所有电影的信息,可以根据自身需求进行储存,这里演示另存为json文件的做法:
const { Builder } = require('selenium-webdriver')
const fs = require('fs')
// ...
;(async ()=> {
// ...
fs.writeFileSync('top250.json', JSON.stringify(movies))
await driver.quit()
})()
最后
当然真正的爬虫需求当然不会像本文一样简单,一般公司级的网站都有做反爬虫处理,反反爬虫才是爬虫岗位中最棘手的工作。
